
What is Machine learning?
Before learning about machine learning, let’s first check the definition of artificial intelligence and how it is roughly divided into categories. Artificial Intelligence (AI) is a system or program that imitates or performs human learning and decision-making, and refers to the implementation of human intelligence in a machine.
Artificial intelligence can mainly be divided into machine learning and rule-based systems. These two approaches operate in different ways and can be used to solve a variety of problems. So let’s take a brief look at these two methods.
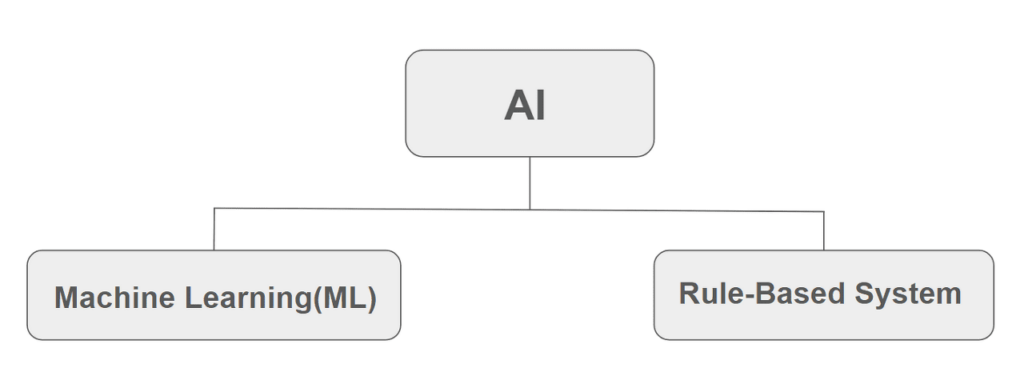
Machine Learning
Machine learning is a method of learning patterns from data to build a model and using this model to make predictions or decisions about new data. The algorithm extracts features from data and uses them to train a model. The trained model receives new data as input and performs prediction or classification. Mainly supervised learning, unsupervised learning, reinforcement learning, etc. are used, and areas of use include speech recognition, image classification, natural language processing, predictive analysis, and recommendation systems.
📢 Since machine learning learns through data, data to learn from is essential!
Rule-Based System
A rule-based system is a method of making decisions based on rules defined by people or experts. Rules have a form such as “if the condition is met, (then) execute like this” and these rules come together to determine the behavior of the entire system. Input data is processed according to predefined rules, and the rules are applied sequentially or selectively according to conditions. Areas of use include expert systems, decision support systems, and business rule management systems.
📢 Foundation-based systems do not require data because they rely on human knowledge!
Now, let’s learn about machine learning in earnest. As mentioned above, machine learning largely includes supervised learning, unsupervised learning, and reinforcement learning. Let’s look at each learning method one by one.
Supervised Learning
Supervised learning is a type of machine learning and is a learning method that uses input data and the correct answer (label or target) for that data to train a model. In supervised learning, a model is designed to predict accurate output for new input by learning the relationship between input and output. Here, model refers to a kind of function (ex : y = f(x)).
In order to train a model in supervised learning, the input value (x) and the corresponding answer or label value (y) must be provided together. This is called training data. Training data is the data set used by the model to learn, and the correct answer or label corresponding to each input value is provided. The model learns relationships or patterns between input values and labels based on training data.
For example, let’s say you’re training a model to recognize handwritten numbers. Several handwriting images are provided as training data, and numbers (labels) corresponding to each image are provided. The model learns the relationship between these images and numbers and is trained to predict numbers for new handwriting images.
When input and label values are provided together like this, the model learns how to predict the relationship between input and output. A model that has completed training can predict accurate output for new input values.
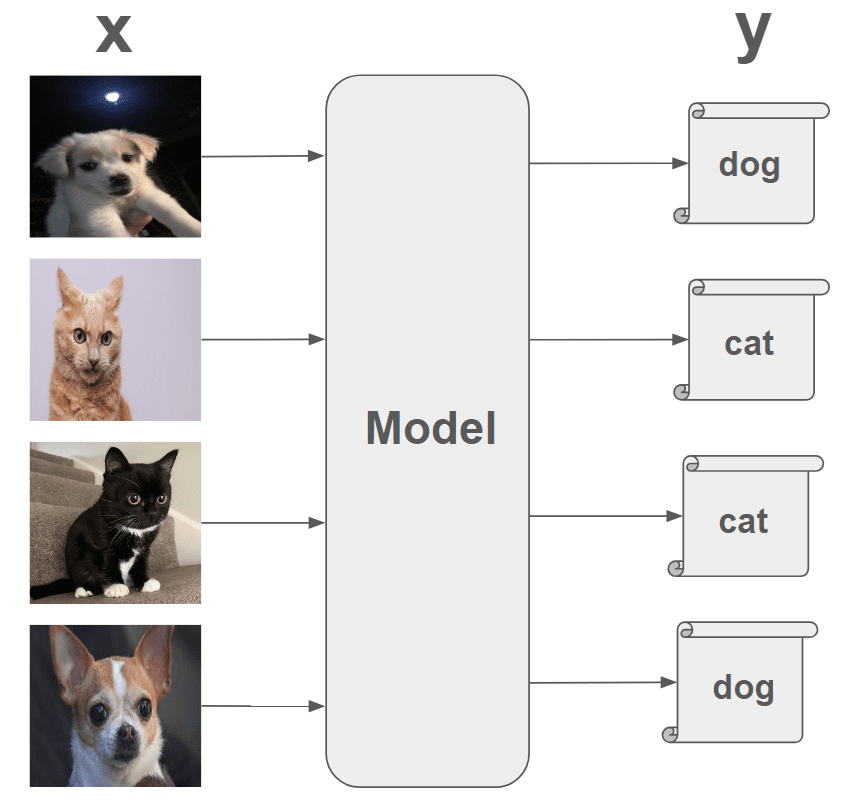
As shown in the image above, you must provide a photo of a dog and a cat corresponding to the x value, and the value corresponding to the correct answer (or label) must be provided as the y value. It is called supervised learning because the correct answer must be provided during the machine learning stage. The machine is provided with labeled (y) photos (x) and learns based on the data.
To summarize, the learning data provided based on the image above is x, and the corresponding correct answer (y) is names such as dog and cat. So, before the machine learns, each photo must be labeled as a cat or a dog. When telling a machine the correct answer, the labeling must actually be numbers (0 and 1) so that the machine can recognize it (e.g. 0 for dog, 1 for cat).
📢 Supervised learning is not possible with unlabeled photos!
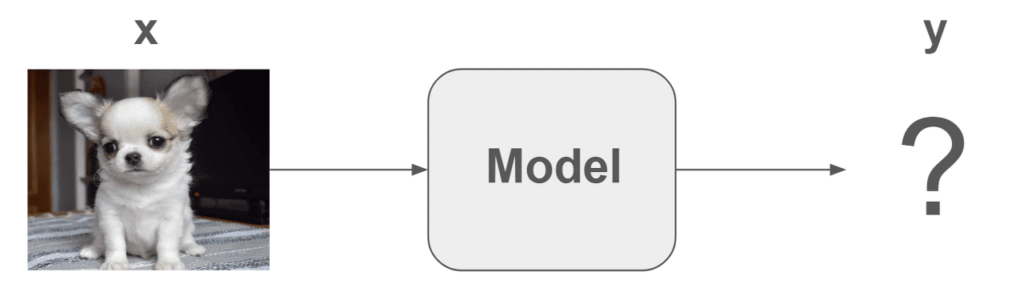
The trained model is used to predict the label y value by inputting the first data x value. If you have trained a model to distinguish between dogs and cats, input a new photo other than the one used for training to make a prediction to distinguish between dogs and cats. Therefore, as learning progresses, accuracy will increase.
Data
Machine learning models generally receive numeric data as input. This is because machine learning models deal with numbers in the process of learning and predicting by performing mathematical operations. Therefore, in order to input various data such as images, voices, and texts into the model, the data must be converted to numbers.
- Image data – A commonly used method is to convert the image into numbers that represent the brightness value of each pixel. In the case of color images, each pixel is expressed as an RGB value or a value in another color space.
- Voice Data – Audio signals are represented as waveforms over time. In general, the waveform is divided into small time intervals to extract the characteristics of the waveform at each time step, and these characteristics are expressed in numbers.
- Text data – Text data is usually expressed as an index of words or characters. Words or characters can be embedded and converted to numbers, or text can be converted to numbers using methods such as one-hot encoding.
Probability
When learning to classify dogs and cats, let’s take an example of a binary classification model that labels dogs as 0 and cats as 1. The model’s output usually appears as a value between 0 and 1. This value represents the probability that the model belongs to that class, and is usually limited to a range between 0 and 1 using a logistic function.
If the output is greater than 0.5, the model is considered to have made a positive prediction for that class. Therefore, if it is greater than 0.5, it can be classified as a cat. Conversely, if it is less than 0.5, the model is considered to have made a negative prediction for that class. Therefore, if it is less than 0.5, it can be classified as a dog. The closer the output value is to 0, the more strongly the model predicts a dog, and the closer it is to 1, the more strongly the model predicts a cat.
In this way, a classification decision is made based on the output of the model. However, this rule may vary depending on the specific model architecture or loss function.

Disadvantages of Supervised Learning
One of the main drawbacks of supervised learning is that it requires labeled data. Labeling refers to the task of assigning an accurate output value or class to each input data. This usually has to be done manually.
There are many cases where judgment is required, which can lead to differences of opinion between people. Additionally, some tasks may require specialized knowledge and may require the participation of experts.
Due to these labeling difficulties, model performance may deteriorate if the dataset is insufficient or the labeling is incorrect. Additionally, labeling new data to correspond to new classes or phenomena can be cumbersome and expensive. To overcome these shortcomings, methods such as automated labeling technology, semi-supervised learning, and self-supervised learning are being studied.
Reinforcement Learning
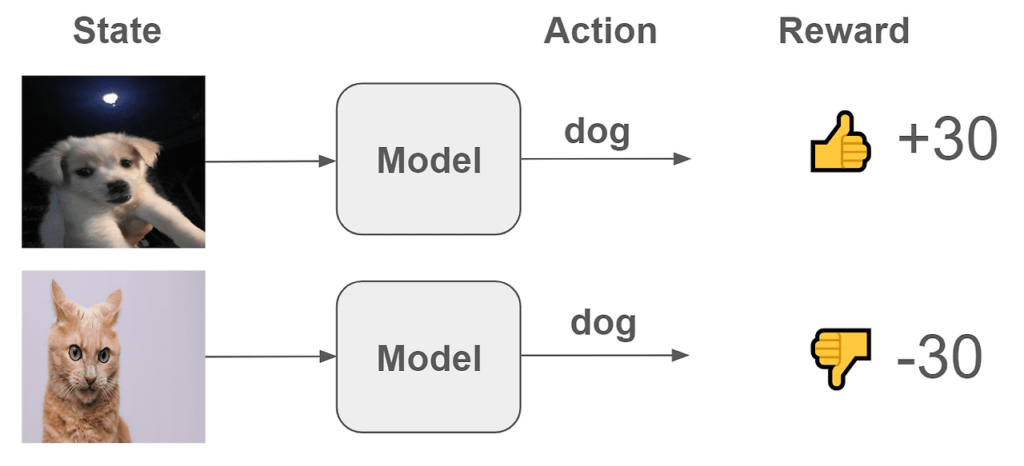
The purpose of reinforcement learning is for the agent to learn optimal behavior in a given environment and maximize accumulated rewards. The agent decides which action to choose based on the current state and receives a reward for doing so.
The core of reinforcement learning is finding the optimal policy, and a policy is a strategy that determines which action to choose in a given state. The model learns a policy, which is a function that receives a given state as input and outputs what action to take. This learned policy is used to select effective actions that can result in high rewards.
At this time, during the learning process, the agent must maintain a balance between exploration and exploitation. Exploration is exploring unknown territory by trying new actions, while exploitation is selecting actions that are already known to have good effects. Finding the optimal policy by striking this balance is one of the tasks of reinforcement learning.
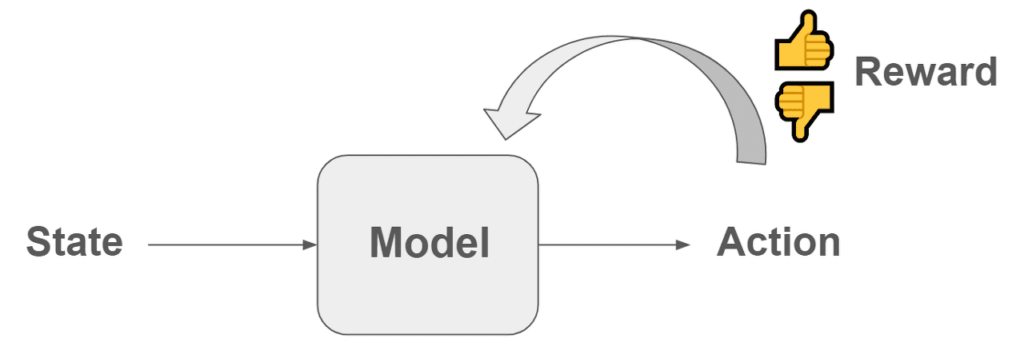
Training
To train a model in reinforcement learning, you must provide a reward corresponding to the action in a specific state. Based on these rewards, the model learns a function A = f(S) that selects actions that can obtain high rewards in a given state.
During the training process, the model learns to find the optimal policy through experience and select actions with higher rewards more often. This reinforcement learning involves the process of improving the model’s ability to select the optimal action in a given state, and A = f(S) represents the function by which the model selects an action in a given state.
predict
The trained reinforcement learning model receives the state value of data seen for the first time as input and is used to predict actions that are expected to result in large rewards. A trained model acquires the ability to select the optimal action in a given state based on learned experience. This model has generalization capabilities and can make useful predictions on new data that was not used for training.
Therefore, for states that are seen for the first time, the model can use trained knowledge to help select the most rewarding action in that state. This is one of the important characteristics that indicates the actual usability and adaptability of reinforcement learning models.
Disadvantages of Reinforcement Learning
A disadvantage of reinforcement learning may be instability. This refers to a phenomenon in which small hyperparameter adjustments or differences in initialization have a significant impact on model performance. The selection of hyperparameters or initial states used in model training can have a significant impact on whether the model converges and the optimal policy, so careful experimentation and adjustment are required to improve performance. This difficulty makes training of reinforcement learning models more complicated and is one of the factors that makes it difficult to predict model performance.
Unsupervised Learning
Unsupervised learning is a type of machine learning that allows models to find patterns or structures in data without being provided with explicit output labels or maps. In other words, the model tries to learn and discover the structure or pattern of the input data on its own. Unsupervised learning is used to identify hidden structures within data or divide data into groups. The main purpose of supervised learning and reinforcement learning is to create a prediction model, but the main purpose of unsupervised learning is to analyze data and extract features.
The two main types of unsupervised learning are
- Clustering – An example of unsupervised learning, a clustering algorithm divides data into groups or clusters with similar characteristics. The goal is to find patterns based on similarities between data. Common clustering algorithms include k-means clustering, hierarchical clustering, and DBSCAN.
- Dimensionality Reduction – Dimensionality reduction is a technology that reduces the complexity of data by converting high-dimensional data to low-dimensional. This allows you to extract important characteristics or conveniently visualize data. Representative dimensionality reduction algorithms include principal component analysis (PCA) and t-SNE.
Unsupervised learning is used in a variety of application areas, such as discovering meaningful structure in data, extracting features, or detecting outliers. For example, you can use clustering to group users with similar interests in fictional media, or dimensionality reduction to extract features from image or text data.
Additionally, unsupervised learning can be used to learn patterns or structures from given data and create new data through this. One of the main unsupervised learning techniques used to train these generative models is Generative Models.
Generative Models
A generative model is a model that generates new data based on the probability distribution learned from training data. These models can generate new samples by mimicking the distribution of training data. Some of the most widely used generative models are
- Variational Autoencoder (VAE) – An extension of the autoencoder, it can learn the characteristics of data and create new data.
- Generative Adversarial Network (GAN) – It consists of two parts: a generator and a discriminator. The generator generates fake data that is indistinguishable from real data, and the discriminator is trained to distinguish between them.
- Boltzmann Machines and Restricted Boltzmann Machines (RBM) – Stochastic energy models can be used to model the probability distribution of data and generate new data based on this.
Data creation and transformation
Additionally, some techniques in unsupervised learning can be used directly to generate or transform data. For example, new data can be created through sampling based on a specific probability distribution, or various types of data can be generated by transforming input data. This generative aspect goes beyond predictive modeling or classification tasks and provides the potential to obtain creative and diverse results by creating or transforming new data.